✅ 데이터가 많은 무한 스크롤(infinite scroll)을 구현할 때 가장 중요하게 고려해야 할 7가지 포인트
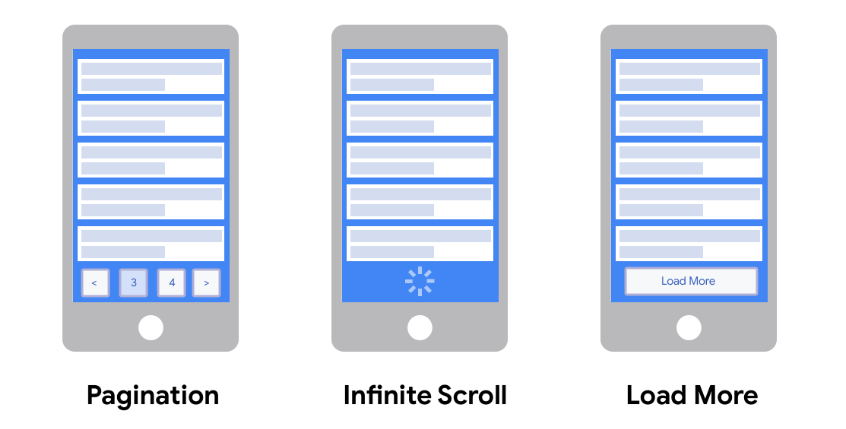
1️⃣ 성능 최적화: 많은 양의 데이터를 처리할 때 성능이 중요합니다. 스크롤 동작이 부드럽고 빠르게 이루어져야 합니다. 데이터를 효율적으로 관리하고, 필요한 만큼만 로드하도록 최적화된 알고리즘을 사용해야 합니다.
2️⃣ 가상화(Virtualization): 대규모 데이터를 가진 리스트나 테이블을 표시할 때 가상화 기술을 사용하면 성능을 향상시킬 수 있습니다. 화면에 보이는 부분만 렌더링하여 메모리 사용량을 최소화하고 스크롤 속도를 높일 수 있습니다.
3️⃣ 데이터 청크(chunk): 모든 데이터를 한 번에 로드하는 것이 아니라 청크(chunk) 단위로 나누어서 로드하는 방식을 사용할 수 있습니다. 이렇게 하면 초기 로딩 시간을 최소화하고 사용자 경험을 향상시킬 수 있습니다.
4️⃣ 스크롤 이벤트 관리: 스크롤 이벤트를 효율적으로 관리하여 필요할 때 데이터를 동적으로 로드하도록 구현해야 합니다. 사용자가 스크롤을 내릴 때마다 데이터를 로드하는 것이 아니라, 스크롤 위치에 따라 필요한 시점에 데이터를 로드하도록 해야 합니다.
5️⃣ 사용자 경험(UX) 고려: 사용자가 스크롤할 때마다 새로운 데이터가 자연스럽게 로드되어야 합니다. 스크롤이 멈춘 시점에 데이터를 로드하면 사용자가 불편함을 느낄 수 있습니다. 따라서 데이터 로드를 사용자가 스크롤할 때 동적으로 처리하는 것이 좋습니다.
6️⃣ 에러 핸들링: 데이터를 로드하는 과정에서 발생할 수 있는 에러를 적절하게 핸들링해야 합니다. 네트워크 에러나 서버 에러 등에 대비하여 사용자에게 적절한 안내를 제공해야 합니다.
7️⃣ 메모리 관리: 무한 스크롤을 구현할 때 메모리 누수(memory leak)를 방지해야 합니다. 필요 없는 데이터나 리소스를 적시에 해제하여 메모리 사용량을 최소화해야 합니다.
이러한 요소들을 고려하여 무한 스크롤을 구현하면 사용자 경험을 향상시키고 성능을 최적화할 수 있습니다.
'기술면접' 카테고리의 다른 글
| 13_Javascript의 호이스팅에 대해 설명해주세요. (0) | 2024.02.15 |
|---|---|
| 12_JSX란 무엇인가요? (0) | 2024.02.14 |
| 10_ 연산자 == & 연산자 === (0) | 2024.02.13 |
| 9_Arrow Function 무엇인가? (0) | 2024.02.13 |
| 8_Async/Await & Promise의 차이 (0) | 2024.02.13 |



